#01 機械学習の基礎
Introduction
(釈迦に説法になる話も多分に含まれるが、限りなく前提知識を0に近づけたいのでご容赦願いたい)
「機械学習」や「ビッグデータ」という言葉を昨今よく耳にするが、機械学習とは一体何だろうか。 Wikipediaから引用してみる。
機械学習(きかいがくしゅう、英: machine learning)とは、人工知能における研究課題の一つで、人間が自然に行っている学習能力と同様の機能をコンピュータで実現しようとする技術・手法のことである。
ここで問題になるのは、どのような手法・アルゴリズムを用いれば計算機で学習を実現できるかということである。 元々人工知能に関する研究は1940年代の頃から始まっており、今日に至るまでの長い道のりの過程で工学的応用を得たのが機械学習と呼ばれる分野である。 まずは人工知能の歴史を軽く追って見ることにする。
人工知能の歴史
Rule-based AI
人工知能というキーワードは1956年のダートマス大学における学会で初めて使われたという。 この頃から人工知能は盛んに研究されており、Alan Turingが有名なチューリングテストを発表したのも1950年のことだった。 チューリングテストとは簡単に言うと、「自分がチャットしている相手が実はコンピュータだったら人工知能と言ってもいいよね」という人工知能のテストである。 実際、1964年頃にMITのJoseph Weizenbaum教授は有名なELIZAというカウンセラーを模した人工知能を実装し、この人工知能は多くの人間を騙すことに成功したという。
ELIZAが実際に行った会話の記録は多く残っているし、今でもEmacsにはdoctorというELIZAのbuilt-in実装が入っている(emacsを起動してEsc - Xでdoctorを実行)。 確かにELIZAの会話は一見人間の精神科医のものかと思ってしまう。 しかし、実際にはパターンマッチングでそれらしい単語(例えば”anxiety”とか”headache”とか)にマッチした場合は用意された回答をし、マッチケースがなければオウム返しをするという、非常にシンプルな作りになっている。
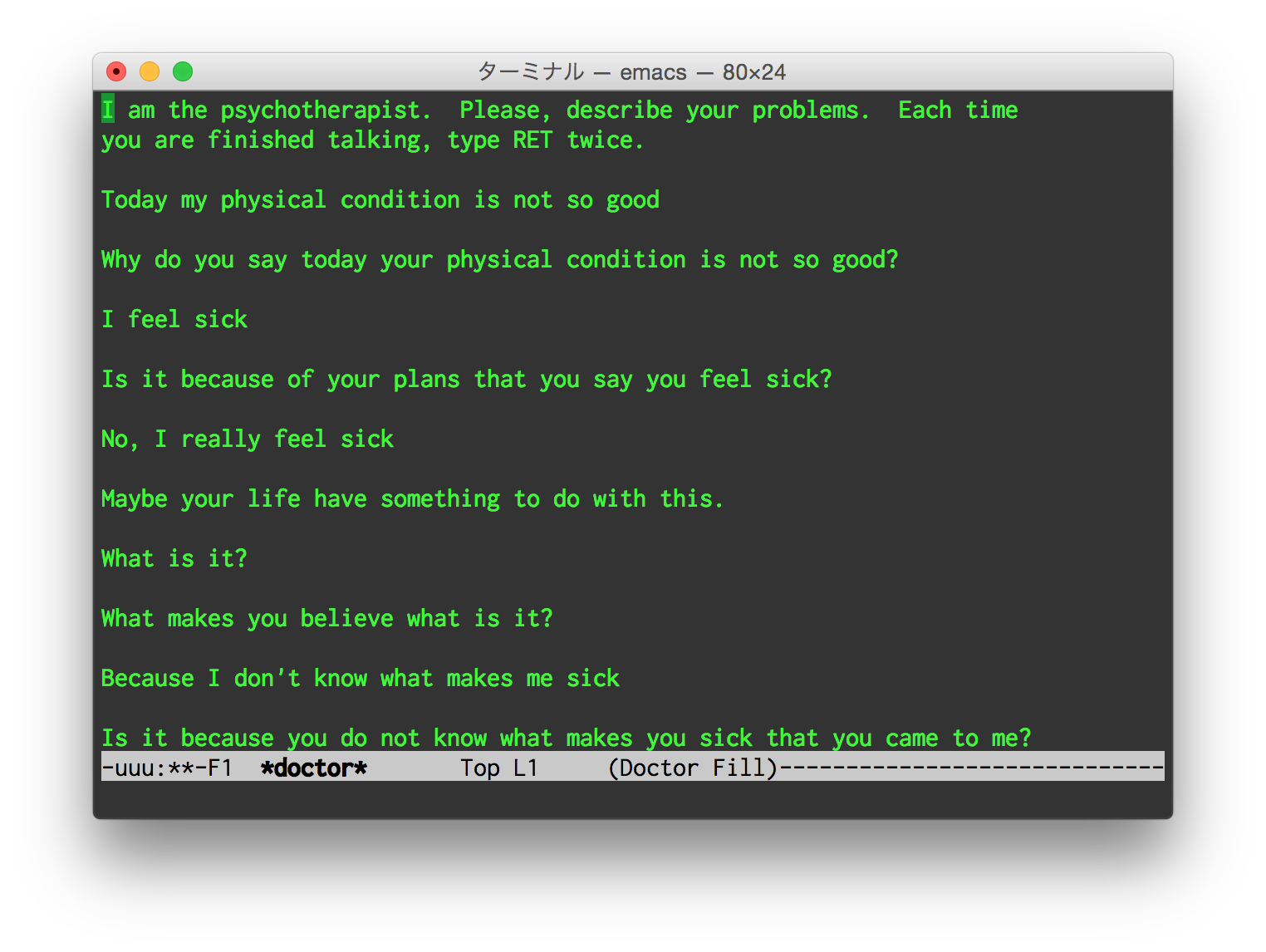
この時期の人工知能は、ELIZAに限らず多くはパターンマッチング(if-then-elseをひたすら連ねたもの)を基本としたrule-basedなAIだった。 Rule-basedなAIでは、より高度な知能に見せるためにはマッチケースをひたすら増やすしかない。
余談だが、「Lispが人工知能研究で用いられた」と言われることがあるが、これは当時まともにパターンマッチングができる言語がLispくらいしかなかったがために、Lispが用いられてきたという歴史的経緯があるようだ。 ELIZAも初期の段階でLisp実装がなされている。
Neural Network
同じ頃、1958年にアメリカの心理学者Frank RosenblattがPerceptronを発表した。 「人工知能を作るなら脳のニューロンの機構を模せばいいではないか」という発想のもと生まれたのが、Perceptronを始めとしたNeural Networkというモデルである。
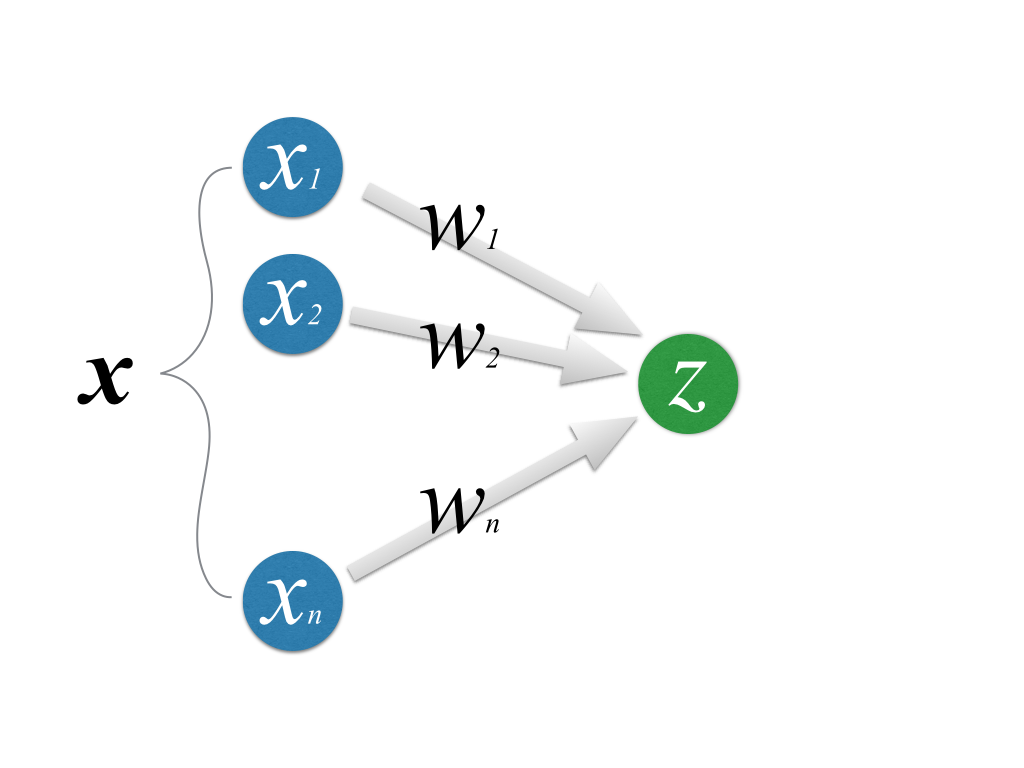
図中の\(x_1 \cdots x_n\)及び\(z\)がニューロンを形式化したもので、左側のニューロンから右側のニューロンへ信号が伝えられている様子をモデル化している。 各入力に\(w_1 \cdots w_n\)という重みをつけて、
\[ z = \sum_{i=1}^n x_i w_i \]
という入力を与える。
しかし、最も単純なパーセプトロンではXOR(排他的論理和)を認識することができない。 この事実(正確には「単純パーセプトロンは線形分離不能なデータを識別できない」こと)は1969年に数学的に証明された。
Neural Network自体は後に扱うので、この辺りで出た不明な単語は気にしなくて良い。
AIの冬
このように少し複雑な問題になると解けなくなってしまうことから人工知能研究への期待は薄れ、国や企業の投資も減っていった。 そのため多くの研究者は人間らしい知能を実現する人工知能(強いAI)の研究を諦め、それまでの研究を実用的なアプリケーション(弱いAI)に活かすことを考えた。 その際によく研究されたのが、光学文字認識や音声認識、機械翻訳などである。 実際、この時期に地道にアルゴリズムが改良され、これらの問題も解くことができるようになっていった。 しかし、実用化されるほどの認識精度にまでは至らなかった。 その大きな理由はデータ不足である。
ビッグデータ時代の幕開け
この状況を打開する出来事が1993年に起こった。 CERNによるWorld Wide Webの一般開放、すなわちインターネットの始まりである。 瞬く間にインターネット上にはテキスト、音声・画像をはじめ、ユーザの行動履歴、天気、株価情報といった広範囲にわたる膨大な量のデータで溢れかえることになった。 こういったデータをアルゴリズムで処理することにより、文字や音声の認識精度はますます向上した。
さらに、ムーアの法則に代表されるようにコンピュータの性能が指数関数的に向上し、大量のデータを高速に処理できるようになった。 あたかもコンピュータが大量のデータを読み込んで学習し、文字や音声を認識しているようにみえることから、機械学習と呼ばれるようになった。
2006年、イギリスのコンピュータ科学者Geoffrey HintonがAuto EncoderとDeep Belief Networkを考案し、これが昨今注目を集めている”Deep Learning”の先駆けとなった。 さらに2011年、Stanford大学のAndrew NgらがGoogleと共同で研究を行った結果、コンピュータクラスタが自力でYouTubeの動画データから猫の概念を認識できるようになったと報告された。 この研究報告によって世界中に衝撃が走り、今日ではDeep Learningをはじめ機械学習の研究が世界中のコンピュータサイエンティストによって行われている。

統計と機械学習
先程パーセプトロンに触れた際に、「あの数式のどこが脳の機構を模しているんだ」と感じた人も少なく無いと思う。 実際のところ、パーセプトロンを始めたNeural Networkは、ネットワーク構造を持ち、各素子がしきい値を持っていること以外はほとんど脳の機構と関係がない。 ではなぜあのようなモデルが用いられるかというと、結局コンピュータは数字を扱うことしかできないからである。 逆に言えば、適切に数字に直すことさえできればあらゆるデータを高速に処理することができるのがコンピュータの強みである。 そのため、今日の機会学習理論の多くは数理統計をベースとしている。
機械学習には様々な種類があるが、その大部分は分類問題である。 先の例だと、文字認識も「与えられた画像をそこに書かれている文字に分類する」問題だし、音声認識も「入力された振幅データがどの音素に相当するのか分類する」ことになる。 その際には
- 予め答えのわかっているデータを学習する
- 未知のデータがどのクラスに分類されるのか推定する
という2段階にわかれている。
学習

例えば上のような元画像が与えられたとき、この画像が「れ」というひらがなであると認識するにはどうすればよいか。 先程も述べたように、結局コンピュータには数字しか扱うことができないから、なんとかしてコンピュータの扱えるような数値データとしてデータの特徴を捉え直す必要がある。 このようにデータからその特徴を数値として取り出すことを特徴抽出という。
一例だが、例えば文字画像を20×20で格子状に区切って各格子で平均をとり、合計400個の濃淡データとして扱う方法がある。 こうすると、例えば「れ」なら「左から30%のあたりに濃度が大きいデータが縦に並んでいる」といった特徴になるわけである。 このデータを400次元空間にmappingすれば、「”れ”は400次元空間のこのあたりに来やすい」みたいな計算をコンピュータで行うことができる。
推定
未知のデータが与えられたときも同じように特徴抽出を行い、既に学習したデータと照らし合わせればクラスに分類することができる。 このときにコンピュータが行っているのも、単純に「このデータは今までのどのデータにより近いのか」という類似度(距離)計算にすぎない(勿論類似度以外で分類するアルゴリズムもある)。
機械学習の学習
当分科会の進め方
ご察しの通り、機械学習ではそれなりに高度な数学(主に解析学、線形代数、確率統計)が要求される。 そのため、この分科会ではおおまかに次のような流れで進めていく。
- 基礎的な確率統計
- 数理統計モデル
- 機械学習の基本的なアルゴリズム
- 最新のトピック(主にDeep Learning)
1年生にとっては難しいこともあると思うが、可能な限り高校レベルの数学で理解可能な丁寧な解説を心がけるし、わからない点があれば遠慮なく質問してほしい (答えられる範囲で回答するよう努力するので)。
理論だけをやると理解しづらいし実感がわきにくいと思うので、できるだけ実例・応用例を見せながら進めたい(希望)。また、回毎に簡単な練習をつけたい(希望)。
この分科会の最終目標として、
- KaggleのcompetitionにTSGの有志で参加したい
- 機械学習を使って何らかしらの認識エンジンを作りたい
という2つを据えておく(希望)。
ちなみに、Kaggleというのは統計解析のコンペティションで、様々な企業が「このデータを解析して欲しい!」といって賞金をつけ、世界中の企業や団体や個人が解析してスコアを競いあうサイトである。
本
参考書というか、僕が読んだ本・読みかけの本で良かったと思う本を挙げておく。 順番に意味はない。
自然科学の統計学
多方面から良書であるとのレビューを聞いている。 教養の「基礎統計」からのつなぎに最適(基礎統計で使われる教科書の続編でもあるし)。
はじめてのパターン認識
一覧性に優れた本で、某書と違ってカバンに入れて持ち運ぶのにはとても適している良書。
説明もわかりやすい。
パターン認識と機械学習
鉄板。だが難しい。避けては通れない一冊。
levelfourは数学が苦手なので、4章くらいまでしかまだ読んでないです。
AIの衝撃
今度は理論書ではなくて普通の新書。機械学習のバックグラウンドやこの先の展望が読みやすく書かれていて面白い。 機械学習を勉強する前に読めばよかったなあと思ってたり。ちなみに2015年3月刊行です。
研究室
折角東大にいるのだから、最先端の研究室に行って教授に話を聞いてみるとよい。というか本当にオススメ。
山西先生
計数工学科の先生。アルゴリズム寄りの研究者で、最近の興味は「潜在情報の抽出」だとか。 つまり、機械学習で得られたパラメータはコンピュータの計算したただの数字でしかないけど、その数字には具体的にどういう意味付けができるか、ということ。
URL: http://ibis.t.u-tokyo.ac.jp/yamanishiken/
杉山先生
情報科学科の先生。去年までは東工大にいらっしゃった。 研究自体はアルゴリズム寄り。「機械学習のアルゴリズムは様々なアプローチからおおよそ研究し尽くされたから、一段上のレイヤから抽象的にアルゴリズムを俯瞰する(要約、曲解あり)」ことを考えているそう。 あとは色々な企業でコンサルもなさってるそうです。
URL: http://www.ms.k.u-tokyo.ac.jp/index-jp.html
中山先生
情報理工学研究科の創造情報学の先生。画像認識・物体認識が専門で、世界的な画像認識のアカデミックコンペに毎年参加されているそうです。
URL: http://www.nlab.ci.i.u-tokyo.ac.jp/
中川先生
情報理工学研究科の数理情報学の先生。最近はプライバシー保護データマイニング(PPDM)がメイン。 「ビッグデータ使って統計するのはいいけど、データに紐付いた個人情報を上手く匿名化しないとマズイよね」的な話。
URL: http://www.r.dl.itc.u-tokyo.ac.jp/
松尾先生
ウェブマイニング、人工知能の専門家。 最近メディアにもよく顔を出して本もたくさん執筆なさっています。書籍部にも平積みにしてあるはずなので読むと良いかも。