#10 事前学習
事前学習
#07,#08のパーセプトロンの問題点の一つとして,初期値をランダムにとっていたことが挙げられる. 度々になるが,勾配法でランダムな初期値からスタートすると,局所解にトラップされてしまう可能性がある.
この問題の解決策として2006年にGeoffery Hintonによって提案されたのが,オートエンコーダである. 着想は,初期値をランダムに取る代わりに最適な初期値を推定することにある. つまり,初期値を選択する操作自体を一つの推定問題として捉えるのである.
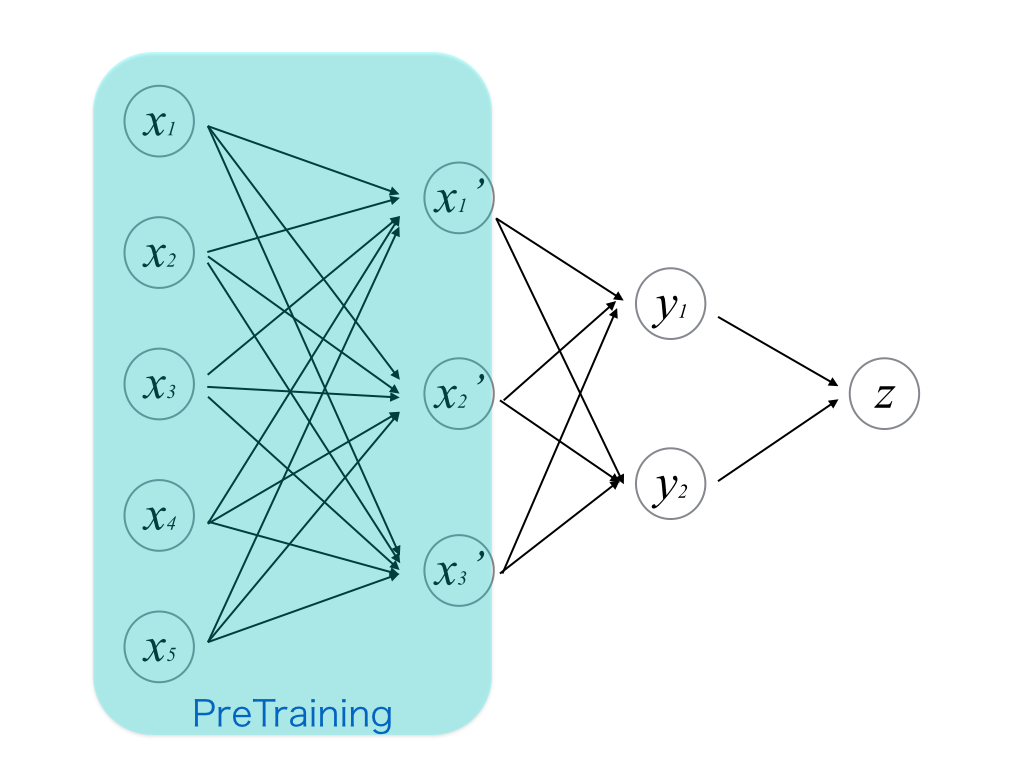
まずはこの図のように最小の層をオートエンコーダとして見立てて,学習を行う. このときのオートエンコーダの重みの初期値はランダムにとる. 学習はパーセプトロンと同様にSGD等を用いて行う.
そして,1層目のパラメータの初期値が推定された状態で,残りの層も含めて教師あり学習を行う. 残りの層の初期値はランダムにとる. これまでのパーセプトロンとの違いは,1層目がオートエンコーダの自己学習を利用して自らパラメータの最適な初期値を学習しているという点である. このようにオートエンコーダを用いてパーセプトロンの重みの初期値を予め推定しておくことを__事前学習(pre-training)__という.
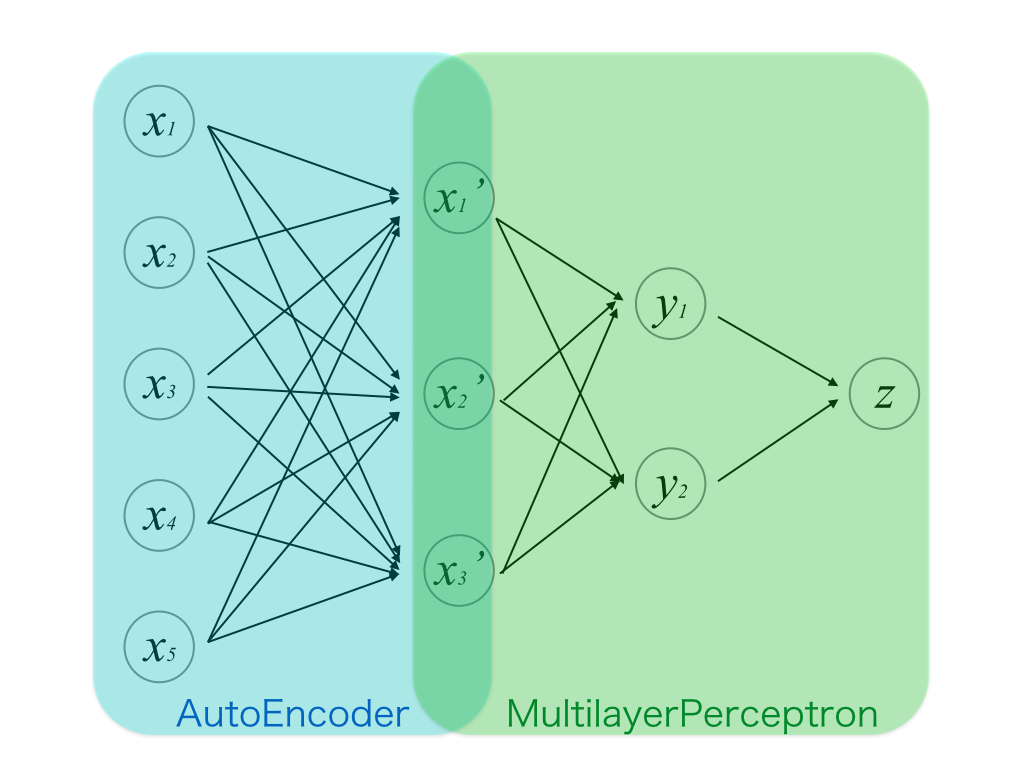
Hintonが初めてオートエンコーダを発表した時は,2000→1000→500→30と3段のオートエンコーダを重ねて,元通りの画像を復元するように学習できた例を示している. 上の例でははじめの1層だけだったが,一般に各層の重みをそれぞれオートエンコーダとみなして事前学習を行うことができる.
【参考】Reducing the Dimensionality of Data with Neural Networks
ちなみに,なぜオートエンコーダを用いるとよい初期値が得られるのか,という点についてはまだ理論的によくわかっていない.
コードによる実例
オートエンコーダ
autoencoder.pyにコードを示す.
基本的なニューラルネットの実装は#08で示したdigit.pyのPerceptronクラスを流用している. AutoEncoderは学習の仕方もほとんどPerceptronと同じなので,Perceptronクラスを継承している(継承しやすいように多少Perceptronクラスは修正した).
class AutoEncoder(Perceptron):
def __init__(self, n_dim=30, eta=0.3, beta=0.01):
Perceptron.__init__(self, nb_mnodes=n_dim, eta=eta, beta=beta)
def fit(self, x):
# 入力信号を教師信号として学習
Perceptron.fit(self, x, x)
def reduce(self, x):
# 中間層出力を得る
return self.s(np.dot(x, self.w.T))
これがAutoEncoderクラスの実装である.
ほとんどPerceptronクラスと同じなのだが,学習を行うメソッドAutoEncoder.fitだけ,教師信号として入力自身を与えるように変更している.
このautoencoder.pyを実行すると,次のようなウインドウが現れる.

左から順に,
- 1列目: 入力ベクトル
- 2列目: オートエンコーダの中間層の出力
- 3列目: 出力ベクトル
となっている.元の入力画像は8×8の64次元で,中間層では一旦16次元まで落としてそれを4×4にconvertして表示している. それを出力層にかけると入力画像に近い画像が得られる.
ちなみに,上から順にそれぞれ9,4,3である.
事前学習
digit.pyにコードを示す.
このコードは,上のautoencoder.pyに更に修正を加えたものになっている. 重要な変更箇所は以下のとおり.
def pretrain(self, x):
# 事前学習
ae = AutoEncoder(n_dim=self.mid_dim, eta=self.eta*0.01)
ae.fit(x)
self.w = ae.weight()
このメソッドが事前学習を行っている.事前学習自体はautoencoder.pyで定義したAutoEncoderクラスに投げている.
事前学習でできた重みベクトル\(\boldsymbol{w}\)をAutoEncoder.weight()で取得し,Perceptronクラスの重みの初期値に設定している.
この新しいPerceptronクラスで数字認識を行うと,90%程度の精度を出すことができる.